开发了一种自动方法DSFusion,通过使用配备鉴别器的基于语言的生成模型,为一个字母或单词生成艺术化的排版。方法结合了对抗性学习和扩散,这有助于确保生成的排版的真实性。
DS-Fusion: Artistic Typography via Discriminated and Stylized Diffusion
Maham Tanveer, Yizhi Wang, Ali Mahdavi-Amiri, Hao Zhang
[Simon Fraser University]
- 介绍了一种新的方法,通过对一个或多个字母字体进行风格化处理来自动生成艺术化的排版,从而在视觉上传达一个输入词的语义,同时确保输出结果保持可读。
- 为了解决手头任务的各种挑战,包括目标冲突(艺术风格化与可读性)、缺乏基础真理和巨大的搜索空间,利用大型语言模型来连接文本和视觉图像的风格化,并建立一个具有扩散模型骨架的无监督生成模型。
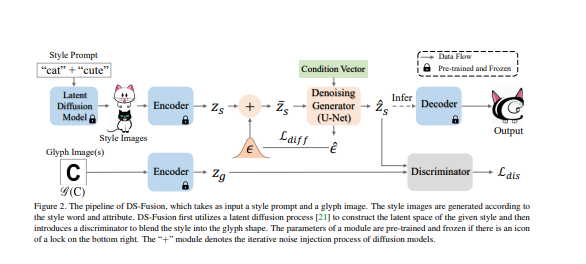
- 具体来说,采用了Latent Diffusion Model(LDM)中的去噪发生器,关键是增加了一个基于CNN的判别器,以适应输入文本的风格。鉴别器使用给定字母/单词字体的光栅化图像作为真实样本,去噪发生器的输出作为假样本。模型被称为DS-Fusion,意为鉴别性和风格化的扩散。
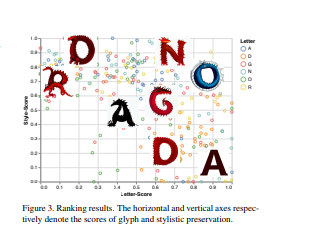
- 通过大量的例子、定性和定量评估以及消融研究,展示了方法的质量和多功能性。用户研究与包括CLIPDraw和DALL-E 2在内的强大基线以及艺术家制作的字体进行比较,证明了DS-Fusion的强大性能。
https://arxiv.org/pdf/2303.09604.pdf




正文完
可以使用微信扫码关注公众号(ID:xzluomor)




 ufabet
มีเกมให้เลือกเล่นมากมาย: เกมเดิมพันหลากหลาย ครบทุกค่ายดัง
ufabet
มีเกมให้เลือกเล่นมากมาย: เกมเดิมพันหลากหลาย ครบทุกค่ายดัง
 tornado crypto mixer
Discover the power of privacy with TornadoCash! Learn how this decentralized mixer ensures your transactions remain confidential.
tornado crypto mixer
Discover the power of privacy with TornadoCash! Learn how this decentralized mixer ensures your transactions remain confidential.
 ดูบอลสด
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
ดูบอลสด
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
 ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
 ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
ดูบอลสด
Pretty! This has been a really wonderful post. Many thanks for providing these details.
 ดูบอลสด
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
ดูบอลสด
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
 Obrazy Sztuka Nowoczesna
Thank you for this wonderful contribution to the topic. Your ability to explain complex ideas simply is admirable.
Obrazy Sztuka Nowoczesna
Thank you for this wonderful contribution to the topic. Your ability to explain complex ideas simply is admirable.
 ufabet
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
ufabet
Hi there to all, for the reason that I am genuinely keen of reading this website’s post to be updated on a regular basis. It carries pleasant stuff.
 ufabet
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.
ufabet
Very well presented. Every quote was awesome and thanks for sharing the content. Keep sharing and keep motivating others.

